Dataset Generation¶
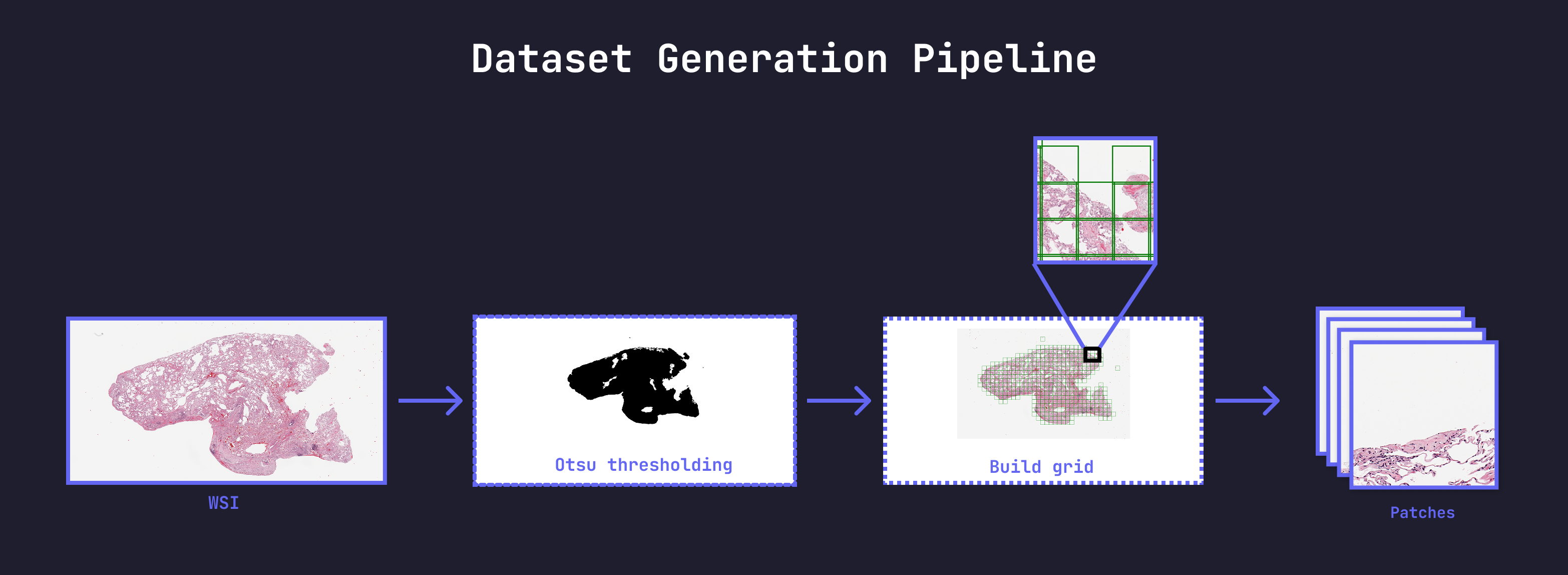
Dataset generation pipeline: slides → tiling → tissue filtering → storage¶
GlassCut provides two approaches for working with tile datasets:
DatasetGenerator¶
The DatasetGenerator processes multiple slides and persists
tiles, thumbnails, and metadata to disk with checkpoint/resume support.
from glasscut import DatasetGenerator, GridTiler
tiler = GridTiler(
tile_size=(512, 512),
magnification=20
)
generator = DatasetGenerator(
dataset_id="my_dataset",
output_dir="./output",
tiler=tiler,
n_workers=4,
batch_size=128,
)
slide_paths = ["slide1.svs", "slide2.svs", "slide3.svs"]
metadata = generator.process_dataset(slide_paths)
print(f"Processed {metadata.total_slides} slides, {metadata.total_tiles} tiles")
Output Structure¶
output/
└── my_dataset/
├── slide_001/
│ ├── tiles/ # Extracted tile PNGs
│ ├── thumbnails/ # Slide thumbnails
│ ├── masks/ # Tissue masks
│ └── slide_metadata.json
├── slide_002/
│ └── ...
├── metadata.json # Dataset-level metadata
└── processed.json # Checkpoint file (for resume)
LiveSlideDataset¶
The LiveSlideDataset keeps tiles in memory for interactive
exploration and prototyping.
from glasscut import LiveSlideDataset, GridTiler
tiler = GridTiler(
tile_size=(512, 512),
magnification=20
)
dataset = LiveSlideDataset(
slide_paths=["slide1.svs", "slide2.svs"],
tiler=tiler,
)
sample = dataset[0] # LiveSlideSample
print(f"Slide: {sample.slide_name}")
print(f"Tiles: {len(sample.tiles)}")